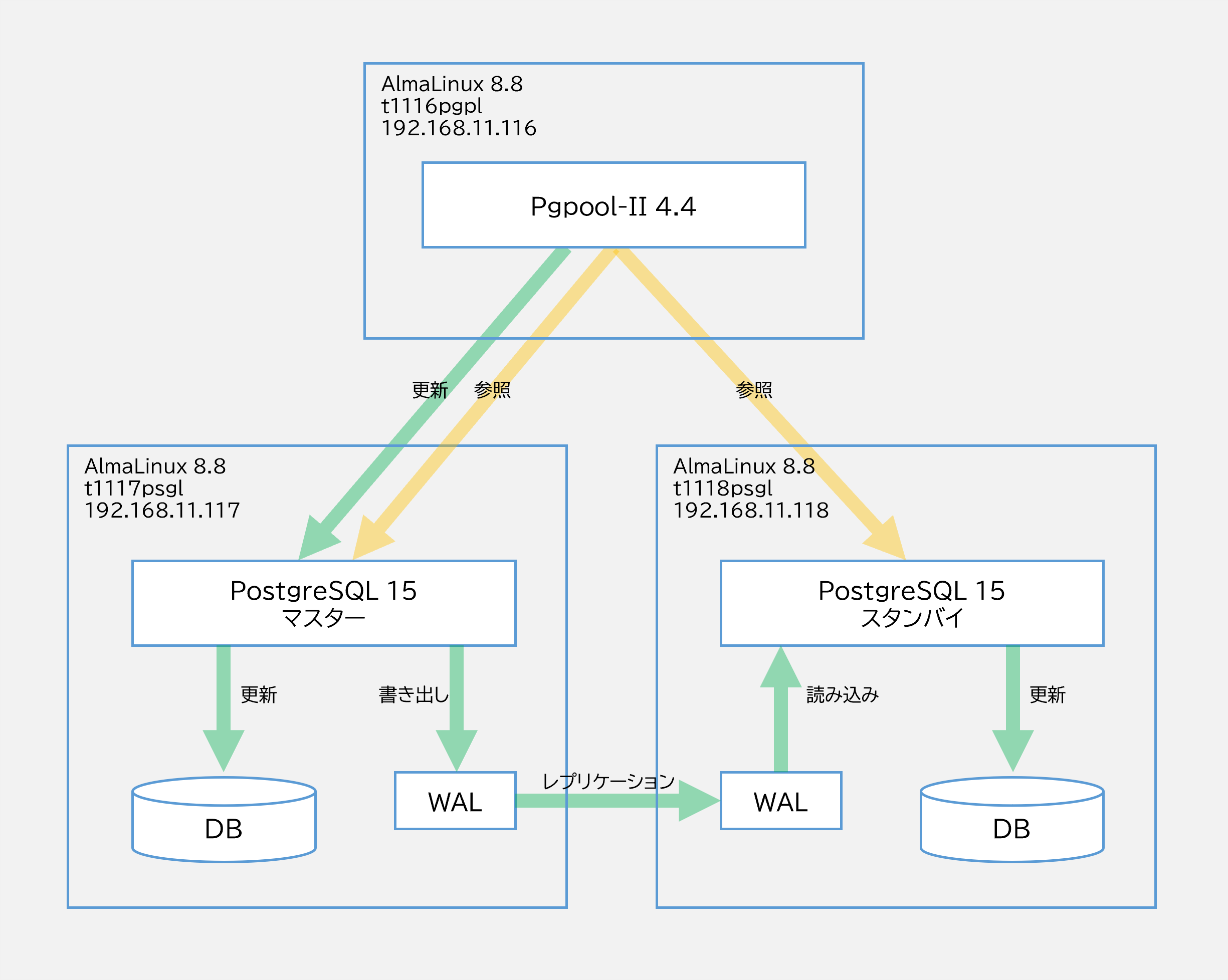
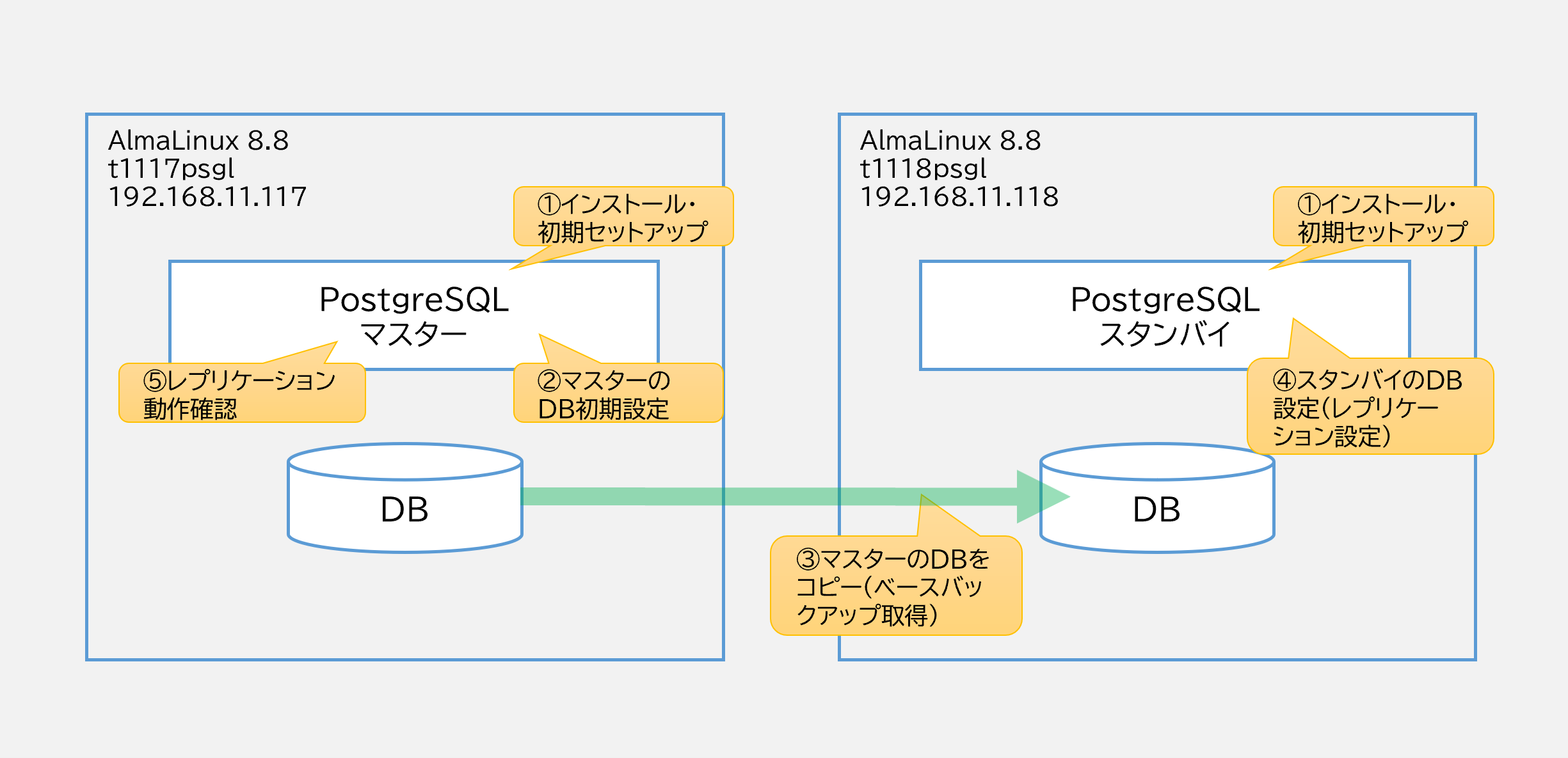
PostgreSQLは「ストリーミングレプリケーション」と呼ばれる構成を取ることで、DBの冗長構成を取ることができる。以前、PostgreSQL 10.xの環境にてストリーミングレプリケーションを構築する手順を記載した。
PostgreSQL 10.xは2017年10月リリースとなっており、かなり古いバージョンであり、結果的にはPostgreSQL 10.xと手順に細かな差異があることを確認した。
本記事ではPostgreSQL 15.xをインストールしてストリーミングレプリケーションを構成する手順を記載する。
環境
OSはRHEL互換OSであるAlmaLinuxを利用し、パッケージ提供されているPostgreSQLを利用する。
- OS : AlmaLinux release 8.8
- PostgreSQL : 15.2
マスターとスタンバイの2台にPostgreSQLをインストールし、ストリーミングレプリケーションを構成する。ホスト名やIPアドレスは以下図を参照いただきたい。
今回はマスターとスタンバイ両方で実施する作業と、片方のみで実施する作業がある。そのため、本記事で記載するプロンプトを以下の通り記載し、作業対象が判別できるようにした。
| プロンプト |
ユーザー |
対象 |
| [Master/Standby]# |
root |
マスターとスタンバイ両方で実施 |
| [Master]# |
root |
マスターのみ実施 |
| [Standby]# |
root |
スタンバイのみ実施 |
| [Master/Standby]$ |
postgres |
マスターとスタンバイ両方で実施 |
| [Master]$ |
postgres |
マスターのみ実施 |
| [Standby]$ |
postgres |
スタンバイのみ実施 |
事前作業として、検証目的なので、firewalldとSELinuxは無効化しておく。
[Master/Standby]# systemctl stop firewalld
[Master/Standby]# systemctl disable firewalld
[Master/Standby]# sed -ie 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
[Master/Standby]# reboot
ストリーミングレプリケーション構成手順概要
PostgreSQLでストリーミングレプリケーションを構成する手順の概要を以下に図示する。
①PostgreSQLインストール・初期セットアップ
1. dnfでPostgreSQLをインストール
まずは、PostgreSQLをインストールする。通常PostgreSQLをRHEL 8にインストールしようとすると、PostgreSQL 10.xがインストールされてしまう。そこで、まずはdnf module enableコマンドでインストールバージョンを選択可能な最新のPostgreSQL 15.xに変更する。
[Master/Standby]# dnf module enable postgresql:15 -y
メタデータの期限切れの最終確認: 5:46:55 前の 2023年08月05日 09時00分46秒 に実施しました。
依存関係が解決しました。
====================================================================================================================================================
パッケージ アーキテクチャー バージョン リポジトリー サイズ
====================================================================================================================================================
モジュールストリームの有効化中:
postgresql 15
トランザクションの概要
====================================================================================================================================================
完了しました!
postgresql-serverがPostgreSQLのDBエンジン本体となり、依存関係でクライアントツール (posgresqlパッケージ) もインストールされる。それ以外に、各種管理用のスクリプトなどが含まれるpostgresql-contribパッケージとPythonでPostgreSQLを接続するために使用するpython3-psycopg2をインストールしておく。
[Master/Standby]# dnf install postgresql-server postgresql-contrib python3-psycopg2 -y
2. postgresユーザーのパスワードを変更
PostgreSQLは原則postgresユーザーにて操作する。パッケージインストール後にpostgresユーザーのパスワードを設定しておこう。
[Master/Standby]# passwd postgres
postgresユーザーのホームディレクトリに、.pgpassファイルを作成する。本ファイルにはレプリケーションで用いるユーザーのパスワード情報が記載されることから、パーミッションも600に設定する。
[Master/Standby]# su - postgres
[Master/Standby]$ cd ~
[Master/Standby]$ vi .pgpass
t1117psgl:5432:*:dbrepl:P@ssw0rd
t1118psgl:5432:*:dbrepl:P@ssw0rd
[Master/Standby]$ chmod 600 .pgpass
[Master/Standby]$ exit
[Master/Standby]#
3. 初期セットアップ
DBの初期データを作成するため、DB初期セットアップコマンドを実行する。/var/lib/pgsql/dataに初期状態のDBが作成される。
[Master/Standby]# postgresql-setup initdb
WARNING: using obsoleted argument syntax, try --help
WARNING: arguments transformed to: postgresql-setup --initdb --unit postgresql
* Initializing database in '/var/lib/pgsql/data'
* Initialized, logs are in /var/lib/pgsql/initdb_postgresql.log
4. DBを起動
一度このタイミングでDBが問題なく起動することを確認しておこう。
[Master/Standby]# systemctl start postgresql
[Master/Standby]# systemctl enable postgresql
5. hostsを登録
Master/Standbyのホスト名とIPアドレスをお互いにhostsファイルへ登録しておく。これは、後程レプリケーションの設定の際にホスト名による登録をするために必要となる。
[Master/Standby]# vi /etc/hosts
192.168.11.117 t1117psgl
192.168.11.118 t1118psgl
6. DBのpostgresユーザーのパスワードを設定
[Master]# su - postgres
[Master]$ psql
postgres=# alter role postgres with password 'P@ssw0rd!';
postgres=# \q
②マスターのDB初期設定
1. マスターにてWALアーカイブログディレクトリ作成
ストリーミングレプリケーションを構成するため、事前にWALアーカイブログを保存するディレクトリを作成する。今回は、/var/lib/pgsql/data/archivedirを保存場所とした。
[Master]# su - postgres
[Master]$ mkdir /var/lib/pgsql/data/archivedir
[Master]$ chmod 700 /var/lib/pgsql/data/archivedir
[Master]$ ls -ld /var/lib/pgsql/data/archivedir
drwx------ 2 postgres postgres 6 6月 5 17:06 /var/lib/pgsql/data/archivedir
2. マスターにてレプリケーション用のDBユーザーを作成
レプリケーション用のDBユーザーを作成する。今回はdbreplというユーザーを作成した。
[Master]$ psql
postgres=# create user dbrepl replication login encrypted password 'P@ssw0rd';
CREATE ROLE
postgres=# \q
3. マスターにて各種設定を実施
次に、マスターにてDBのレプリケーションに必要な各種設定を実施する。設定前に、念のため変更前の設定ファイルをバックアップしておこう。
[Master]$ cp /var/lib/pgsql/data/postgresql.conf ~/postgresql.conf.org
[Master]$ cp /var/lib/pgsql/data/pg_hba.conf ~/pg_hba.conf.org
以下にpostgresql.confにおいて変更する設定値を記載する。なお、PostgreSQL 10.xでは、レプリケーションの設定をrecovery.confという名称の別ファイルで保存していたが、PostgreSQL 15.xではpostgresql.confに統合されている。
postgresql.conf
PostgreSQLの各種設定を変更するため、postgresql.confを更新する。以下に設定内容の概要を記載する。
| 設定項目 |
設定内容 |
| listen_addresses |
DBが接続を受け付けるIPアドレスを指定する。サーバが持つすべてのIPアドレスで接続を許可する場合は、*を指定する。 |
| wal_level |
replicaで指定する。 |
| synchronous_commit |
DBに更新があった際に、どこまで更新が反映されたら応答を返すかを設定する。例えば、localの場合はマスターでWALがディスクに記録されたら応答を返す。onの場合はスタンバイに転送されたWALがディスクに記録されたのちに応答を返す。今回は、onで設定する。 |
| archive_mode |
スタンバイのレプリケーションが長期間停止した際に、マスター側のWALが削除された場合は、WALアーカイブログを使う可能性があるため、WALアーカイブログを有効にする。ストリーミングレプリケーションの場合はalwaysに設定すればよさそうだ。 |
| archive_command |
WALアーカイブログを出力時に、WALをコピーするためのコマンドを指定する。 |
| max_wal_senders |
スタンバイから接続を許可する接続数の最大値を設定する。スタンバイ1台の構成であるため、10に設定すれば十分となる。 |
| wal_keep_size |
ストリーミングレプリケーション用に保持するWALのファイルのサイズ (MB)。PostgreSQL 10.xまではwal_keep_segmentsという設定項目となっていたが、本値はwal_keep_segments x wal_segment_size (デフォルト16MB)で計算可能となる。今回は30 x 16MB = 480MBとした。 |
| synchronous_standby_names |
スタンバイのリストを記載する。スタンバイを識別する名称は、後述するprimary_conninfoの設定値で設定したapplication_nameとなる。今回はフェイルオーバー時の設定簡素化のため、* (all) で設定する。 |
| hot_standby |
ストリーミングレプリケーションを有効にするためonに設定する。 |
| lc_messages |
PostgreSQLのエラーメッセージを日本語から英語に変更する場合は、Cで設定する。この変更は任意である。 |
| restore_command |
本設定はスタンバイ側だけ有効になる値となる (マスターでは無視される)。ストリーミングレプリケーションでWALアーカイブログを用いる場合のコピーコマンドを指定する。今回は、scpコマンドを利用する。scp実行時にパスワードを聞かれないようにするため、後程SSHキーの交換を行っておく。 |
| recovery_target_timeline |
本設定はスタンバイ側だけ有効になる値となる (マスターでは無視される)。ストリーミングレプリケーションの場合はlatestを設定する。 |
| primary_conninfo |
本設定はスタンバイ側だけ有効になる値となる (マスターでは無視される)。application_nameは今回は「スタンバイのホスト名」を設定する。user・passwordは前の手順で作成したレプリケーション用DBユーザーを指定する。host・portは接続先となる「マスターのホスト名」とポート番号 (デフォルト5432) を指定する。 |
[Master]$ cd $PGDATA
[Master]$ vi postgresql.conf
listen_addresses = '*'
↑★すべてのIPアドレスで接続を許可
wal_level = replica ←★replicaで設定
synchronous_commit = on ←★onで設定
archive_mode = always ←★alwaysで設定
archive_command = 'test ! -f /var/lib/pgsql/data/archivedir/%f && cp %p /var/lib/pgsql/data/archivedir/%f'
↑★上記で設定
max_wal_senders = 10 ←★10で設定
wal_keep_size = 480 ←★480 (MB) で設定
synchronous_standby_names = '*' ←★* (all) で設定
hot_standby = on ←★onで設定
lc_messages = 'C' ←★エラーメッセージを日本語から英語にするため変更
restore_command = 'scp -o StrictHostKeyChecking=no t1117psgl:/var/lib/pgsql/data/archivedir/%f %p'
↑★上記で設定
recovery_target_timeline = latest ←★latestで設定
primary_conninfo = 'application_name=t1118psgl user=dbrepl passfile=''/var/lib/pgsql/.pgpass'' host=t1117psgl port=5432'
↑★上記で設定
pg_hba.conf
PostgreSQLにスタンバイからの接続許可を行うため、pg_hba.confに追記する。なお、PostgreSQL 15.xでは、暗号化認証方式のデフォルト設定は、md5ではなくscram-sha-256になっているので、レプリケーションの認証設定もscram-sha-256を採用する。
[Master]$ cd $PGDATA
[Master]$ vi pg_hba.conf
~(中略)~
host replication dbrepl 192.168.11.117/32 scram-sha-256
host replication dbrepl 192.168.11.118/32 scram-sha-256
4. マスターのDB再起動
設定反映するため、DBを再起動する。一部設定はリロードでは反映されないため、必ず再起動を実施しよう。
[Master]$ systemctl restart postgresql
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ====
'postgresql.service'を再起動するには認証が必要です。
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ====
③マスターのDBをスタンバイにコピー(ベースバックアップ取得)
1. マスターのDBをスタンバイにコピー(ベースバックアップ取得)
スタンバイはマスターからベースバックアップを取得することで、初期設定と初期データのコピーを行う。コピーはPostgreSQLのバックアップ機能であるベースバックアップを使用する。
ベースバックアップを取得するため、スタンバイのDBを一度停止する。
[Standby]# systemctl stop postgresql
DB初期化時に作成されたデータをすべて削除してから、pg_basebackupコマンドを用いてマスターのベースバックアップを直接コピーする。
[Standby]# su - postgres
[Standby]$ rm -rf /var/lib/pgsql/data/*
[Standby]$ pg_basebackup -D /var/lib/pgsql/data -h t1117psgl -X stream -c fast -U dbrepl -w
[Standby]$ echo $?
0 ←★0であることを確認
④スタンバイのDB設定(レプリケーション設定)
1. スタンバイを示すファイル(standby.signal)を作成
DBをスタンバイとして動作させるためのファイルとして、standby.signalという名称の空ファイルを作成する。
[Standby]$ touch /var/lib/pgsql/data/standby.signal
2. マスターとスタンバイのSSHキーを互いに交換
スタンバイからマスターのアーカイブログを取得する際にscpコマンドを使うため、その際にパスワードを聞かれないよう、SSHキーの交換を行っておく。
マスター
[Master]$ ssh-keygen
[Master]$ ssh-copy-id 192.168.11.118
スタンバイ
[Standby]$ ssh-keygen
[Standby]$ ssh-copy-id 192.168.11.117
3. スタンバイのDBを起動
以上で準備が整ったので、停止していたスタンバイのDBを起動する。
[Standby]$ systemctl start postgresql
==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units ====
'postgresql.service'を開始するには認証が必要です。
Authenticating as: root
Password:
==== AUTHENTICATION COMPLETE ====
4. マスターにてレプリケーション状態確認
起動後、マスターにてレプリケーションの状態確認を行う。レプリケーションが開始されると、pg_stat_replicationテーブルにレコードが記載される。もし、なにも表示されない場合は、何らかの理由でレプリケーションが正常にできていないことを意味する。
[Master]$ psql -x -c "SELECT * FROM pg_stat_replication;"
-[ RECORD 1 ]----+------------------------------
pid | 35349
usesysid | 16384
usename | dbrepl
application_name | t1118psgl
client_addr | 192.168.11.118
client_hostname |
client_port | 41536
backend_start | 2023-08-21 07:59:42.847297+09
backend_xmin |
state | streaming ←★streamingであることを確認
sent_lsn | 0/1B000148
write_lsn | 0/1B000148
flush_lsn | 0/1B000148
replay_lsn | 0/1B000148
write_lag |
flush_lag |
replay_lag |
sync_priority | 1
sync_state | sync ←★syncであることを確認
reply_time | 2023-08-23 21:25:27.104786+09
⑤レプリケーション動作確認
1. マスターにてDB及びテーブルを作成
それでは、実際にマスターにて更新した内容がストリーミングレプリケーションによってスタンバイ側に反映されることを確認しよう。
まず、テスト用DBとしてtestdbを作成する。
[Master]$ psql -l
データベース一覧
名前 | 所有者 | エンコーディング | 照合順序 | Ctype(変換演算子) | ICUロケール | ロケールプロバイダー | アクセス権限
-----------+----------+------------------+-------------+-------------------+-------------+----------------------+-----------------------
postgres | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | | libc |
template0 | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
(3 行)
[Master]$ createdb testdb
[Master]$ psql -l
データベース一覧
名前 | 所有者 | エンコーディング | 照合順序 | Ctype(変換演算子) | ICUロケール | ロケールプロバイダー | アクセス権限
-----------+----------+------------------+-------------+-------------------+-------------+----------------------+-----------------------
postgres | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | | libc |
template0 | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | | libc | =c/postgres +
| | | | | | | postgres=CTc/postgres
testdb | postgres | UTF8 | ja_JP.UTF-8 | ja_JP.UTF-8 | | libc |
(4 行)
次に、testdbに対してテーブルmytableを作成する。mytableはidとnameの二つの列を持つシンプルなテーブルとしている。
[Master]$ psql -d testdb
testdb=# \dt
リレーションが見つかりませんでした。
testdb=# create table mytable (id integer primary key, name varchar(20));
CREATE TABLE
testdb=# \dt
リレーション一覧
スキーマ | 名前 | タイプ | 所有者
----------+---------+----------+----------
public | mytable | テーブル | postgres
(1 行)
testdb=# \q
2. スタンバイにレプリケーションされることを確認
作成したテーブルmytableに対して、レコードを3行登録する。
[Master]$ psql -d testdb -c "insert into mytable (id, name) values (1, 'Ichiro');"
[Master]$ psql -d testdb -c "insert into mytable (id, name) values (2, 'Jiro');"
[Master]$ psql -d testdb -c "insert into mytable (id, name) values (3, 'Saburo');"
[Master]$ psql -d testdb -c "select * from mytable;"
id | name
----+--------
1 | Ichiro
2 | Jiro
3 | Saburo
(3 行)
スタンバイで確認すると、3行のレコードが存在することを確認できる。
[Standby]$ psql -d testdb -c "select * from mytable;"
id | name
----+--------
1 | Ichiro
2 | Jiro
3 | Saburo
(3 行)
なお、スタンバイは参照のみ可能となるため、以下の通りDBの更新を行うとエラーとなり失敗する点に注意しよう。
[Standby]$ psql -d testdb -c "insert into mytable (id, name) values (4, 'Shiro');"
ERROR: cannot execute INSERT in a read-only transaction
以上で、PostgreSQL 15.xをインストールしてストリーミングレプリケーションを構成する手順は完了となる。
次回は、ストリーミングレプリケーション構成のPostgreSQLをPgpool-IIで管理するための構築手順を記載する。
参照